HadoopをWindows 7で動かす!分散処理システムの構築

Hadoopは、大量のデータを高速に処理するためのオープンソースの分散処理フレームワークであり、多くの企業や研究機関で利用されています。しかし、一般的にHadoopはLinux環境での動作が推奨されており、Windows上で動作させるにはいくつかの課題があります。本記事では、Windows 7でHadoopを稼働させ、分散処理システムを構築する手順を詳細に解説します。これにより、Windows 7ユーザーも容易にHadoopのパワーを活用できるようになります。
HadoopをWindows 7で動かす手順とポイント
Windows 7でHadoopを動かすためには、いくつかの手順とポイントに注意する必要があります。ここでは、具体的な手順とテクニックを詳しく解説します。
前提条件と環境設定
Windows 7でHadoopを動かす前に、以下の前提条件を満たしていることを確認してください。
- Javaのインストール(Java Development Kit, JDK)
- Windows用のHadoopバージョンのダウンロード
- 環境変数(JAVA HOME, HADOOP HOME)の設定
Javaのインストールは必須で、Hadoopの動作に必要です。また、環境変数の設定はHadoopが正しく動作するための重要なステップです。
Hadoopのインストール手順
HadoopをWindows 7にインストールする手順は以下の通りです。
- Hadoopのバイナリファイルをダウンロードし、適当なディレクトリに解凍します。
- 環境変数(HADOOP HOME)を設定し、%PATH%にHadoopのbinディレクトリを追加します。
- Hadoopの設定ファイル(core-site.xml, hdfs-site.xml)を編集します。
Hadoopの設定ファイルでは、fs.defaultFSやdfs.replicationなどのパラメータを指定します。これらの設定が正しくないと、Hadoopが動作しない可能性があります。
フォーマットとクラスタの起動
Hadoopのフォーマットとクラスタの起動は以下のコマンドで行います。
- HDFSをフォーマットする:
hadoop namenode -format - Hadoopのクラスタを起動する:
start-dfs.shとstart-yarn.sh
HDFSのフォーマットはHadoopのファイルシステムを初期化するステップで、最初の起動時に実行する必要があります。
簡単なテスト:WordCountを実行
Hadoopが正しく動作していることを確認するために、WordCountという基本的なサンプルプログラムを実行します。
- 入力ファイルを作成し、HDFSにアップロードします。
- WordCountを実行する:
hadoop jar hadoop-examples.jar wordcount /input /output - 出力ファイルをHDFSからダウンロードして確認します。
WordCountはHadoopの分散処理機能をテストする基本的な方法で、成功した場合はHadoopが正しく動作していることを確認できます。
問題解決とトラブルシューティング
HadoopをWindows 7で動かす際に遭遇する一般的な問題と対処方法は以下の通りです。
- JavaのPATHが正しく設定されていない:環境変数を確認し、必要に応じて修正します。
- Hadoopの設定ファイルに誤りがある:設定ファイルを再確認し、必要に応じて修正します。
- ポートが使用中:使用されているポートを解放するか、Hadoopの設定で別のポートを使用します。
問題解決にはログのチェックが重要です。Hadoopのログはエラーメッセージや警告を含むため、トラブルシューティングに役立ちます。
| 問題 | 対処方法 |
|---|---|
| JavaのPATHが正しく設定されていない | 環境変数を確認し、必要に応じて修正 |
| Hadoopの設定ファイルに誤りがある | 設定ファイルを再確認し、必要に応じて修正 |
| ポートが使用中 | 使用されているポートを解放するか、Hadoopの設定で別のポートを使用 |
| メモリ不足 | Hadoopのメモリ設定を増やし、必要に応じてPCのメモリを増設 |
| ファイルシステムのエラー | HDFSのフォーマットを再度実行し、ファイルシステムの整合性を確認 |
Hadoopのシステム構成は?
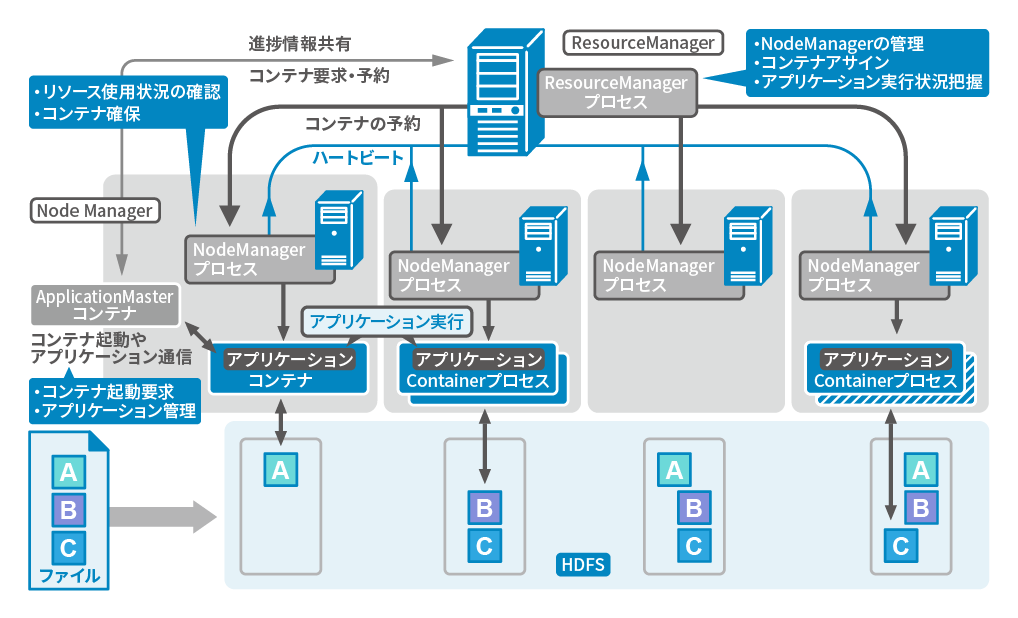
Hadoopのシステム構成は、主にデータの分散処理と存储を実現するために設計されたフレームワークです。Hadoopは大きくHDFS (Hadoop Distributed File System)、MapReduce、そしてYARN (Yet Another Resource Negotiator)という3つの主要なコンポーネントで構成されています。HDFSはデータを信頼性高く分散して格納し、MapReduceは大量のデータを効率的に処理するために使用されます。YARNはリソース管理とジョブスケジューリングの役割を果たします。
1. HDFS (Hadoop Distributed File System)
HDFSは、大量のデータを信頼性高く分散して格納するために設計されたファイルシステムです。HDFSは Namenode と Datanode の2つの主要なノードで構成されています。
- Namenodeはメタデータを管理し、ファイルのロケーション情報を保持します。
- Datanodeは実際のデータを格納し、Namenodeの指示に従ってデータの読み書きを行います。
- HDFSはレプリケーションを用いてデータの信頼性を確保します。通常、データは3つのコピーが作成され、異なるDatanodeに分散して格納されます。
2. MapReduce
MapReduceは、大量のデータを並列処理するために設計されたプログラミングモデルです。MapReduceジョブはMapとReduceの2つの主要なフェーズに分けられます。
- Mapフェーズでは、入力データが分割され、各マッパーがデータを処理して中間キーと値のペアを生成します。
- Reduceフェーズでは、中間キーと値のペアがリデューサーに送られ、最終的な出力が生成されます。
- MapReduceはシャッフルとソートというプロセスを用いて、マッパーとリデューサー間の中間データを効率的に処理します。
3. YARN (Yet Another Resource Negotiator)
YARNは、Hadoopのリソース管理とジョブスケジューリングのために設計されたフレームワークです。YARNはResourceManager、NodeManager、およびApplicationMasterで構成されています。
- ResourceManagerはクラスタ全体のリソースを管理し、アプリケーションにリソースを割り当てます。
- NodeManagerは各ノードで実行され、リソースの使用状況を監視し、ResourceManagerの指示に従ってタスクをスケジュールします。
- ApplicationMasterは各アプリケーションごとに生成され、アプリケーション内のタスクを管理し、ResourceManagerとNodeManagerとの間の通信を仲介します。
Hadoopの最新バージョンは?
![]()
Hadoopの最新バージョンは3.3.4です。
Hadoop 3.3.4の主な特徴
Hadoop 3.3.4は、安定性とパフォーマンスを向上させるために数々のバグ修正と機能追加が行われました。主な変更点には、YARNの信頼性向上、HDFSの拡張性改善、Hadoop FileSystem APIの強化が含まれています。
- YARNの峻別スケジューリングのパフォーマンスが向上しました。
- HDFSの故障検出と障害回復のメカニズムが強化されました。
- 新しいFileSystem APIが導入され、より柔軟なストレージ統合が可能になりました。
Hadoop 3.3.4のインストール手順
Hadoop 3.3.4のインストールは、公式ウェブサイトからバイナリパッケージをダウンロードし、解凍するところから始まります。その他の手順には、Javaのインストール、環境変数の設定、Hadoop設定ファイルの編集が含まれます。
- Javaを最新のバージョンに更新し、環境変数PATHに追加します。
- Hadoopのconfディレクトリにあるhadoop-env.shとcore-site.xmlを編集します。
- クラスターの各ノードでhadoopサービスを起動します。
Hadoop 3.3.4の新機能と改善点
Hadoop 3.3.4では、セキュリティとクラウド統合に重点が置かれました。セキュリティ面では、 Kerberos認証の強化や暗号化</strongの改善が行われ、クラウド統合面では、AWS S3とAzure Storageとの互換性が向上しました。
- 新しいIdentity and Access Management (IAM)ポリシーが導入され、AWSとの統合が容易になりました。
- Azure Storageとの接続が高速化し、大容量データの転送が効率的になりました。
- 暗号化アルゴリズムが強化され、データの保護がより堅牢になりました。
Haddop 使い道?
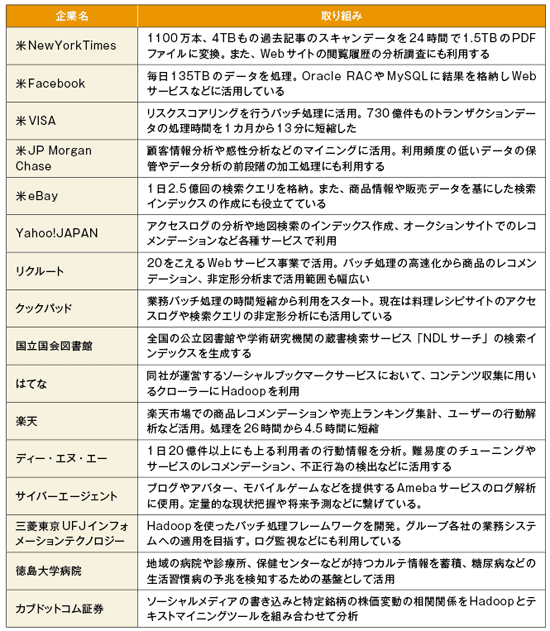
Hadoopは、ビッグデータを処理するための強力なオープンソースのフレームワークです。主に、大量のデータを分散環境で効率的に処理するための機能を提供しています。Hadoopの主な特徴は、HDFS(Hadoop Distributed File System)とMapReduceです。HDFSはデータを冗長性と耐障害性を備えた分散ファイルシステムで管理し、MapReduceはデータ処理を並列化して分散環境で効率的に実行します。Hadoopは、データの保管、処理、分析に利用され、企業や研究機関で広く採用されています。
Hadoopの基本的な構成要素
Hadoopの基本的な構成要素には以下の3つがあります。
- HDFS(Hadoop Distributed File System):大容量のデータを冗長性と耐障害性を備えた分散ファイルシステムで管理します。
- MapReduce:データ処理を並列化して効率的に実行するためのプログラミングモデルです。
- YARN(Yet Another Resource Negotiator):リソースの管理と分散アプリケーションのスケジューリングを担当します。
Hadoopの主な用途
Hadoopは、大規模なデータ処理と分析に役立ちます。
- データの保管と管理:Hadoopは、PB(ペタバイト)単位のデータを効率的に保管することができます。
- データの処理と分析:MapReduceを使用することで、大量のデータを高速に処理・分析できます。
- リアルタイム分析:HadoopのサブプロジェクトであるHBaseやSparkとともに使用することで、リアルタイムのデータ分析も可能になります。
Hadoopの導入と活用のメリット
Hadoopを導入することで、多くのメリットが得られます。
- コスト効率の向上:低廉なハードウェアで大量のデータを処理できるため、コスト効率が向上します。
- 耐障害性の向上:データの冗長性と分散処理により、システムの耐障害性が向上します。
- スケーラビリティの向上:追加のノードを簡単に追加することで、スケーラビリティが向上します。
よくある疑問
HadoopをWindows 7で動かすにはどのような手順が必要ですか?
HadoopをWindows 7で動かすには、まずJava Development Kit (JDK)のインストールが必要です。次に、Hadoopのバイナリファイルをダウンロードし、適切なディレクトリに解凍します。更に、環境変数の設定を行い、Hadoopの設定ファイルを編集してWindows環境に合わせます。最後に、Hadoopクラスターを起動して機能を確認します。
Windows 7でHadoopを動かす際、どのような問題が一般的に起こり得ますか?
Windows 7でHadoopを動かす際、一般的に互換性問題やパフォーマンス問題が生じることがあります。更に、Hadoopのネイティブライブラリのサポートが不十分な場合や、セキュリティ設定が厳しすぎるためにプロセスが正常に実行されないことがあります。これらの問題は、設定の調整や追加のソフトウェアをインストールすることで解決できます。
Hadoopの分散処理システムをWindows 7で構築する際のメリットは何ですか?
Windows 7でHadoopの分散処理システムを構築する主なメリットは、既存のWindows環境を活用できることです。これにより、新たなハードウェア投資を抑えることができ、また、Windowsに精通した開発者がHadoopを導入しやすくなります。さらに、Windowsユーザーインターフェースと統合することで、管理や操作がよりシンプルになります。
Windows 7でHadoopを動かす際にどのようにセキュリティを確保できますか?
Windows 7でHadoopを動かす際にセキュリティを確保する方法には、システムのファイアウォール設定を適切に調整し、不要なポートの通信を遮断することが挙げられます。さらに、Hadoopクラスターへのアクセス制御を設定し、認証と認可の仕組みを強化します。また、定期的なセキュリティパッチの適用も重要な対策となります。
コメントを残す